Ridurre - Convolutional Filter Pruning
Ridurre - Convolutional Filter Pruning
- 4 minsPruning is the process when we try to shrink a network by removing the redundant and “not so significant” filters.
The Ridurre package is a mini-framework which you can easily use on your existing Keras models, and also you can define your own pruning methods without any struggle.
The use of the package can be visualized in the following way:
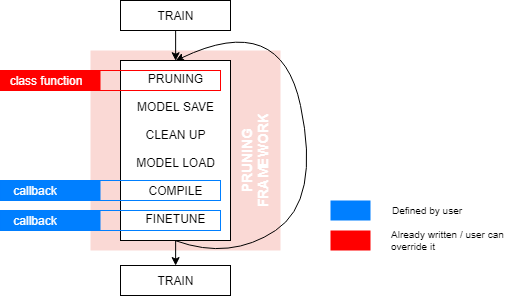
Therefore the steps in a pruning process:
- Training - This is where we fit a CNN for a certain time on the dataset to reach the sufficient accuracy/loss.
- Pruning - With a trained model we can observe the filters in every convolutinal layer (one-by-one) and calculate some metric which can be the basis of the decision, which filters are not necessary. The chosen filters will be removed from the layers.
- Fine-Tuning - With the previous step, we removed some knowledge from our network. With an optimal pruning decision this is just a small fraction of the whole, but still, we would like the network to recover. So a one (or few) epoch training could help in this process.
- Post-Training - We can call this a longer recovery step from the whole pruning. It is not always needed but it won’t hurt the model if we are doing it.
Now we can see how the method is done with these simple steps, let’s talk about the metric which was mentioned before.
Pruning Metrics
You can think about almost anything which can be a metric for pruning. The question is, which one is better than the others. One of the best solution would be to measure the correlation of the filters and the loss/accuracy: which filter can I drop in order to have the least change in accuracy. This is called the Oracle Pruning and yes, this is a brute force solution which would take a lot of time to execute.
So we need other solutions which can reduce this time and this means, we need to make calculations on the filters which can rank those in a layer from least to most important. I would like to summarize my favourite two of them, which you can try out in the Ridurre package.
- Random Pruning - The best of the bests. This pruning is exactly what you are thinking of. There is no metric calculation and whatsoever. We just define a pruning factor and randomly choose one (or few) filters which we can “delete”. $\text{Number of Filters to Prune} = |\text{filters}| * \text{pruning factor}$. This can look like a waste of time but actually it is worth the try as it is a real competition to other methods [1]. Implementation
- KMeans Pruning - We can take all the filters in a convolutional layer and use unsupervised clustering, again with some pruning factor. Now we can define a number of clusters, and for every cluster centroid we will keep the closes data point, which is a filter. The intuition behind this method, is that we “compress” the knowledge with keeping the most representative one and deleting the others in a cluster. Implementation
There are a lot others which can bring great results, but keep in mind that the baseline should be an already (mmanually) small network or the random pruning which is the simplest among them.
Case Study - Cifar10 with a ResNet20
Why Cifar10 and a shallow network?
(Unfortunately) with my hardware, this is what I could run, but in the future I would like to produce better results with not just classification, but object detection, semantic segmentation and keypoint detection.
With that being said I will let the plots do the talking for me. This case study is available as an example for the package.
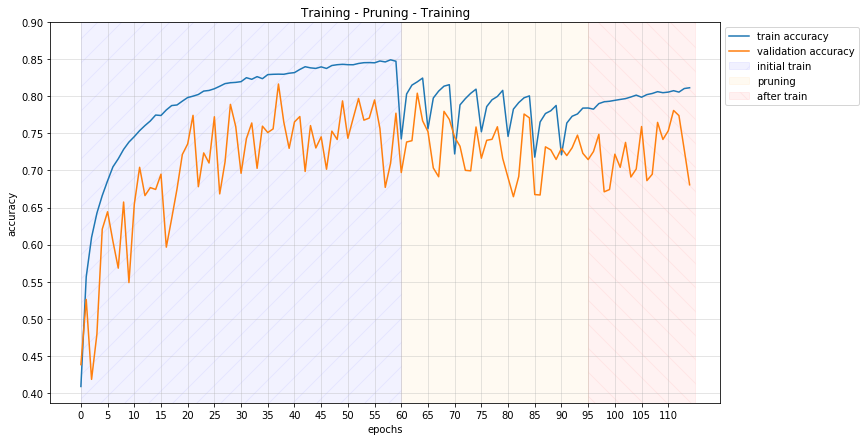
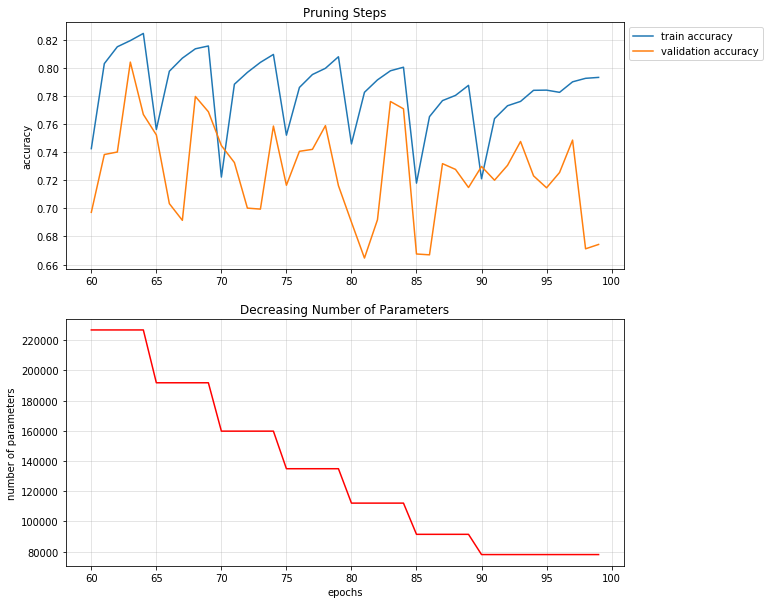
As we can see the train and validation accuracy dropped at the end of the pruning, but by just a little in contrast with the parameter loss. Initially we had $220.000$ parameters which was reduced below $80.000$ which means almost $64%$ reduction. Also it is worth saying that this example is a pretty aggressive pruning as we remove filters from every layer with $\text{clustering factor} = 0.9$. So at the end of the pruning our first few layers will have $10$ filters instead of the original $16$.
A more sufficient process would be to freeze the first few layers and have a soft pruning factor. That way we could have shorter fine-tunings and the model could stay more accurate, but of course it would take more time to prune.
I hope you enjoyed this project and you will use or at least try out the Ridurre package.
References
[1] - Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks

Gábor Vecsei
I love chocolate