Finding patterns in stock data with similarity matching - Stock Pattern Analyzer
Find similar patterns in historical stock data
- 8 minsIn financial (or almost any type of) forecasting we build models which learn the patterns of the given series. Partially this can be done because the investors and traders tend to make the same choices they did in the past, as they follow the same analysis techniques and their objective rules (e.g.: if a given stock drop below $x$, then I’ll sell). Just look at the textbook examples below [1].
Algorithmic trading, which covers ~80% [8] [9] of the trading activity introduces similar patterns as they often based on the same techniques and fundamentals. These can be observed at different scales (e.g. high-frequency trading)
In this pet-project I wanted to create a tool with which we can directly explore the most similar patterns in $N$ series given a $q$ query. The idea was that, if I look at the last $M$ trading days for a selected stock, and I find the most similar matches from the other $N$ stocks where I also know the “future” values (which comes after the $M$ days), then it can give me a hint on how the selected stock will move in the future. For example, I can observe the top $k$ matches, and then a majority vote could decide, if a bullish or bearish period will come.
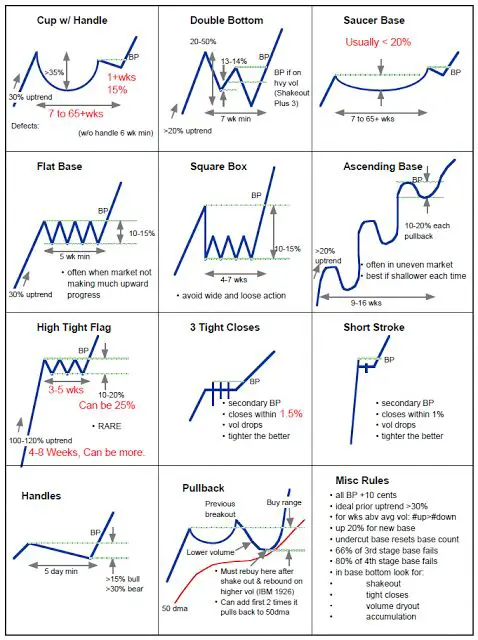
(Source: [1])
Search Engine
The approach would be quite simple if we would’t care about runtime. Just imagine a sliding window over all stocks which you select, then a calculation of some distance metric and bummm 💥, you have the closest matches. But we want better than that, as even a 1 second response time can be depressing for an end user. Let’s get to how it can be “optimized”.
Instead of the naive sliding window approach which has the biggest runtime complexity, we can use more advanced similarity search methods [2]. In the project I used 2 different solutions:
- KDTree [7] [3]
- Faiss Quantized Index [4]
Both are blazing ⚡ fast compared to the basic approach. The only drawback is that you need to build a data model to enable this speed and keep it in the memory. As long as you don’t care how much memory is allocated, you can choose which ever you want. But when you do, I’d recommend the quantized approximate similarity search from Faiss. You can quantize your data and by that you can reduce the memory footprint of the objects with more than a magnitude. Of course the price is that this is an approximate solution [2], but still, you will get satisfying results. At least this was the case in this stock similarity search project.
You can see the comparison of the different solutions at the measurements section.
Window extraction
To build a search model for a given length (measured in days) which we call dimensions, you’ll need to prepare the data in which you would like to search in later on. In our case this means a sliding window [6] across the data with a single step. To speed it up we can vectorize this step with numpy:
window_indices = np.arange(values.shape[0] - window_size + 1)[:, None] + np.arange(window_size)
extracted_windows = values[window_indices]
Now that we have the extracted windows we can build the search model. But wait… It’s sounds great that we have the windows, but we actually don’t care about the “real 💲💲💲 values” for a given window. We are interested in the patterns, the ups 📈🦧 and downs 📉. We can solve this by min-max scaling the values for each window (this is also vectorized). This way we can directly compare the patterns in them.
Building the search tree/index is different for each library, with scipy’s cKDTree it looks like this:
X = min_max_scale(extracted_windows)
# At this point the shape of X is: (n_windows, dimensions)
model = cKDTree(X)
(To build a Faiss index, you can check the code at my repo)
The RAM allocations and build times are compared below in the measurements section.
Query
We have a search model, now we can start to use it to find the most similar patterns in our dataset. We only need to define a constant $k$ which defines how many (approximate) top-results we would like to receive and a min-max scaled query which has the same dimensions as the data we used to build the model.
top_k_distances, top_k_indices = model.query(x=query_values, k=5)
The query speed of the models can be found in the measurement table below.
Measurement results
| Build Time (ms) | Memory Footprint (Mb) | Query Speed (ms) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| window sizes | 5 | 10 | 20 | 50 | 100 | 5 | 10 | 20 | 50 | 100 | 5 | 10 | 20 | 50 | 100 |
| FastIndex | 0.80 | 1.30 | 1.81 | 13.57 | 26.98 | 3.48 | 6.96 | 13.92 | 34.80 | 69.58 | 1.03 | 1.27 | 2.47 | 7.79 | 15.56 |
| MemoryEfficientIndex | 6967.66 | 7058.32 | 5959.26 | 8216.05 | 7485.01 | 2.27 | 2.28 | 2.12 | 2.33 | 2.22 | 0.23 | 0.35 | 0.25 | 0.23 | 0.42 |
| cKDTreeIndex | 110.23 | 135.16 | 206.76 | 319.94 | 484.34 | 10.60 | 17.57 | 31.49 | 73.24 | 142.80 | 0.08 | 1.38 | 24.68 | 30.82 | 40.92 |
- RAM allocation measurements are over-approximations
- Search object is serialized then the size of the file is reported here
- Measurements were done on an average laptop (Lenovo Y520 with a “medium” HW config)
- No GPUs were used, all calculations are made on CPUs
- Query speed is measured as the average of 10 queries with the given model
The tool
Now that we have the search models, we can build the whole tool. There are 2 different parts:
- RestAPI (FastAPI) - as the backend - this allows us to search in the stocks
- Dash client app - as the frontend
- I had to use this to quickly create a shiny frontend (I am more of a backend guy 😉) but ideally this should be a React frontend which is responsive and looks much better

RestAPI
When we start the stock-API, a bunch of stocks (S&P500 and a few additional ones) are downloaded, prepared, and then we start to build the above mentioned search models. For each length we would like to investigate, a new model gets created with the appropriate dimensions. To speed up the process, we can download and create the models in parallel (with concurrent.futures).
For the simplicity of this tool, 2X a day (because of the different markets) a background scheduled process updates both the stock data and then the search models. In a more advanced (not MVP) version you would only need to download the last values for each stock after market close, create an extra sliding window which contains the new values and then add it to the search model. This would save you bandwidth and some CPU power. In my code, I just re-download everything and re-build the search models 😅.
After starting the script, the endpoints are visible at localhost:8001/docs.
Client Dash app
I really can’t say anything interesting about this, I tried to keep the code at minimum while the site is usable and looks pretty (as long as you are using a desktop).
Dash is perfect to quickly create frontends if you know how to use plotly, but for a production scale app as I mentioned I would go with Reach, Angular or any other alternative.
Making trading decisions based on the patters
Please just don’t. I mean it is really fun to look at the graphs and check what are the most similar stocks out there and what patterns can you find, but let’s be honest:
This will only fuel your confirmation bias.
A weighted ensamble of different forecasting techniques would be my first go-to method 🤫.
My only advice: Hold 💎👐💎👐
Demo & Code
You can find a Demo, which is deployed to Heroku. Maybe you’ll need to wait a few minutes befor the page “wakes up”.
You can find the code in my Stock Pattern Analyzer GitHub repo:
References
[1] Trading Patterns Cheat Sheet
[2] Benchmarking nearest neighbors
[3] Scipy cKDTree
[5] Big Lessons from FAISS - Vlad Feinberg
[6] What is Sliding Window Algorithm?
[8] Algo Trading Dominates 80% Of Stock Market
[9] Algorithmic trading - Wikipedia
🚀🚀🌑

Gábor Vecsei
I love chocolate